A2 & A3 Flashcards
In a stochastic framework, explain why the Cape Cod method is preferred over the LDF method when few data points exist
Clark The Cape Cod method is preferred since it requires the estimation of fewer parameters. Since the LDF method requires a parameter for each AY, as well as the parameters for the growth curve, it tends to be over-parameterized when few data points exist.
Provide three advantages of using parameterized curves to describe loss emergence patterns.
Clark 1. Estimation is simple since we only have to estimate two parameters 2. We can use data from triangles that do not have evenly spaced evaluation data 3. The final pattern is smooth and does not follow random movements in the historical age to age factors
Briefly describe the two components of the variance of the actual loss emergence.
Clark Process Variance - the random variation in the actual loss emergence Parameter Variance - the uncertainty in the estimator
Provide two advantages of using the over-dispersed Poisson distribution to model the actual loss emergence.
Clark 1) Inclusion of scaling factors allows us to match the first and second moments of any distribution. Thus, there is high flexibility. 2) Maximum likelihood estimation produces the LDF and Cape Cod estimates of ultimate losses. Thus, the results can be presented in a familiar format.
Describe the key assumptions underlying the model outlined in Clark.
Assumption 1) Incremental losses are independent and identically distributed. Assumption 2) The variance/mean scale parameter is fixed and known Assumption 3) Variance estimates are based on an approximation to the Rao-Cramer lower bound
Briefly describe three graphical tests that can be used to validate Clark’s model assumptions.
Plot the normalized residuals against the following 3 variables. If the residuals for each graph are randomly scattered around zero with a roughly constant variance, we can assume the following: Incremental age - growth curve appropriate expected loss in each increment age - variance/mean ratio is constant calendar year - no calendar year effects
Briefly explain why it might be necessary to truncate LDFs when using growth curves.
Clark For curves with heavy tails (ex. loglogistic), it may be necessary to truncate the LDF at a finite point in time to reduce reliance on the extrapolation.
Compare and contrast the process and parameter variances of the Cape Cod method and the LDF method.
Clark Process variance - the CC method produces a higher process variance than the LDF method since it does not use a separate parameter for each AY. This leads to larger difference between expected loss emergence and actual loss emergence. Parameter variance - the CC method produces a lower parameter variance than the LDF method since it requires few parameters.
An actuary used maximum likelihood to parameterize a reserving model. Due to management discretion, the carried reserves differ from the maximum likelihood estimate. Explain why it may not be appropriate to use the coefficient of variation in the model to describe the carried reserve.
Clark Since the standard deviation in the MLE model is directly tied to the maximum likelihood estimate, it may not appropriate for the carried reserves.
An actuary used maximum likelihood to parameterize a reserving model. Due to management discretion, the carried reserves differ from the maximum likelihood estimate. Explain why it may be appropriate to use the coefficient of variation in the model to describe the carried reserve.
Clark Since the final carried reserve is a selection based on a number of factors, it stands to reason that the standard deviation should also be a selection. The output from the MLE model is a reasonable basis for that selection.
Briefly describe two problems with using the normal distribution as an approximation to the true distribution of R
If the data is skewed it is a poor approximation The confidence interval can have negative lower limits, even if negative reserve is not possible Mack 1994
To calculate the standard error of loss reserves using Mack’s method, we use the following formula:
One drawback of the formula above is that it does not provide an estimator for alpha(I-1)
Provide three options for calculating alpha(I-1)
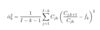
Mack 1994

Identify an alternative to normal distribution for R that avoids its problems
Lognormal Mack 1994
Provide three different variance assumptions for Cik.
Mack 1994

For each variance assumption, provide the formula for the corresponding estimator for fk and briefly describe the estimator in words.
Mack 1994

Describe a graphical variance test that can be employed in order to determine the appropriate fk estimator to use.
Mack 1994
